# load packages
library(tidyverse) # for data wrangling and visualization
library(broom) # for formatting model output
library(scales) # for pretty axis labels
library(knitr) # for pretty tables
library(kableExtra) # also for pretty tables
library(patchwork) # arrange plots
# Spotify Dataset
spotify <- read_csv("../data/spotify-popular.csv")
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 20))SLR: Mathematical models for inference
Prof. Eric Friedlander
Application exercise
📋 AE 07: Mathematical Models: Navigate to Deepnote
Complete Exercises 0-2.
Mathematical models for inference
Topics
Define mathematical models to conduct inference for the slope
Use mathematical models to
calculate confidence interval for the slope
conduct a hypothesis test for the slope
calculate confidence intervals for predictions
Computational setup
The regression model, revisited
spotify_fit <- lm(danceability ~ duration_ms, data = spotify)
tidy(spotify_fit) |>
kable(digits = 10, format.args = list(scientifi = TRUE))| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
Inference, revisited
- Earlier we computed a confidence interval and conducted a hypothesis test via simulation:
- CI: Bootstrap the observed sample to simulate the distribution of the slope
- HT: Permute the observed sample to simulate the distribution of the slope under the assumption that the null hypothesis is true
- Now we’ll do these based on theoretical results, i.e., by using the Central Limit Theorem to define the distribution of the slope and use features (shape, center, spread) of this distribution to compute bounds of the confidence interval and the p-value for the hypothesis test
Mathematical representation of the model
\[ \begin{aligned} Y &= Model + Error \\ &= f(X) + \epsilon \\ &= \mu_{Y|X} + \epsilon \\ &= \beta_0 + \beta_1 X + \epsilon \end{aligned} \]
where the errors are independent and normally distributed:
- independent: Knowing the error term for one observation doesn’t tell you anything about the error term for another observation
- normally distributed: \(\epsilon \sim N(0, \sigma_\epsilon^2)\)
Mathematical representation, visualized
\[ Y|X \sim N(\beta_0 + \beta_1 X, \sigma_\epsilon^2) \]
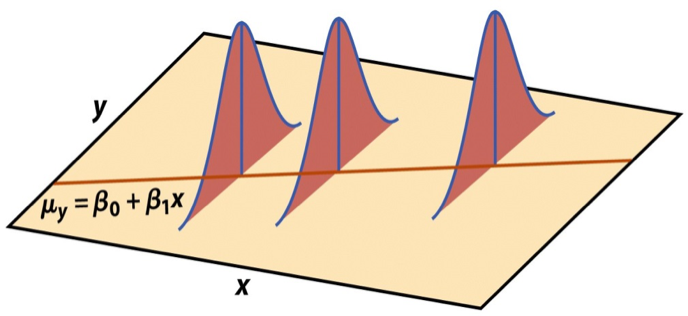
- Mean: \(\beta_0 + \beta_1 X\), the predicted value based on the regression model
- Variance: \(\sigma_\epsilon^2\), constant across the range of \(X\)
- How do we estimate \(\sigma_\epsilon^2\)?
Regression standard error
Once we fit the model, we can use the residuals to estimate the regression standard error, the average distance between the observed values and the regression line
\[ \hat{\sigma}_\epsilon = \sqrt{\frac{\sum_\limits{i=1}^n(y_i - \hat{y}_i)^2}{n-2}} = \sqrt{\frac{\sum_\limits{i=1}^ne_i^2}{n-2}} \]
- We divide by \(n - 2\) because we have \(n-2\) degrees of freedom
Why do we care about the value of the regression standard error?
Standard error of \(\hat{\beta}_1\)
The standard error of \(\hat{\beta}_1\) quantifies the sampling variability in the estimated slopes
\[ SE_{\hat{\beta}_1} = \hat{\sigma}_\epsilon\sqrt{\frac{1}{(n-1)s_X^2}} \]
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
Mathematical models for inference for \(\beta_1\)
Hypothesis test for the slope
Hypotheses: \(H_0: \beta_1 = 0\) vs. \(H_A: \beta_1 \ne 0\)
Test statistic: Number of standard errors the estimate is away from the null
\[ T = \frac{\text{Estimate - Null Value}}{\text{Standard error}} \\ \]
p-value: Probability of observing a test statistic at least as extreme (in the direction of the alternative hypothesis) from the null value as the one observed
\[ \text{p-value} = P(|T| > |\text{test statistic}|), \]
calculated from a \(t\) distribution with \(n - 2\) degrees of freedom
Hypothesis test: Test statistic
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
\[ T = \frac{\hat{\beta}_1 - 0}{SE_{\hat{\beta}_1}} = \frac{-4.04\times 10^{-7} - 0}{1.28\times 10^{-7}} \approx -3.15 \]
Our observed slope, \(\hat{\beta_1} = -4.04\times 10^{-7}\), is \(3.15\) standard errors below what we would expect if there were no linear relationship between duration_ms and danceability.
Complete Exercise 3.
Hypothesis test: p-value
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
Hypothesis test: p-value
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
The probability of obtaining an observed slope providing stronger evidence for the alternative hypothesis, if we assume that the null hypothesis is true, is \(1.72\times 10^{-3}\).
Understanding the p-value
| Magnitude of p-value | Interpretation |
|---|---|
| p-value < 0.01 | strong evidence against \(H_0\) |
| 0.01 < p-value < 0.05 | moderate evidence against \(H_0\) |
| 0.05 < p-value < 0.1 | weak evidence against \(H_0\) |
| p-value > 0.1 | effectively no evidence against \(H_0\) |
Important
These are general guidelines. The strength of evidence depends on the context of the problem.
Hypothesis test: Conclusion, in context
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
- The data provide convincing evidence that the population slope \(\beta_1\) is different from 0.
- The data provide convincing evidence of a linear relationship between the duration of a song and it’s danceability.
Complete Exercises 4-6.
Confidence interval for the slope
\[ \text{Estimate} \pm \text{ (critical value) } \times \text{SE} \]
\[ \hat{\beta}_1 \pm t^* \times SE_{\hat{\beta}_1} \]
where \(t^*\) is calculated from a \(t\) distribution with \(n-2\) degrees of freedom
Confidence interval: Critical value
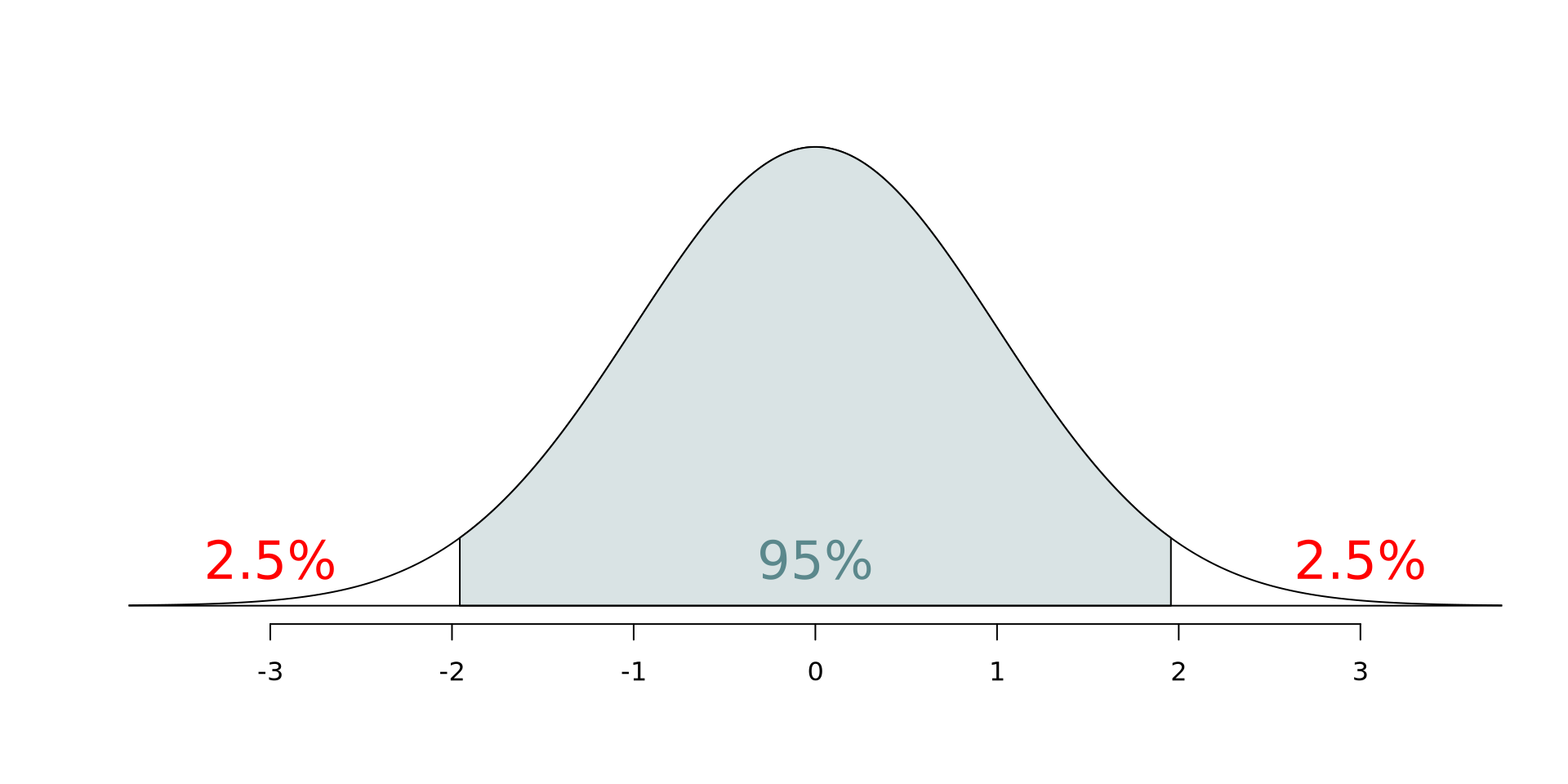
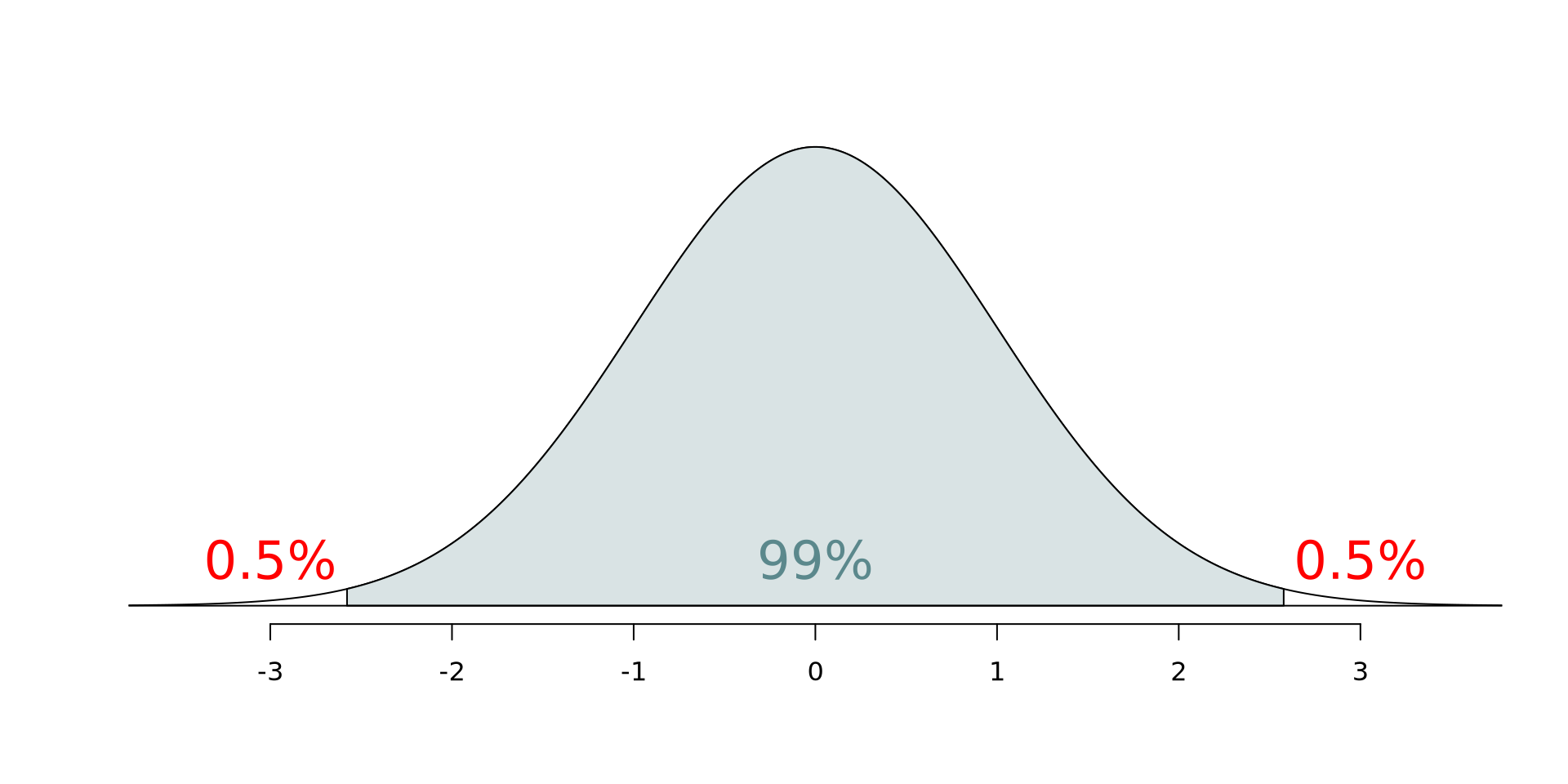
95% CI for the slope: Calculation
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |
\[\hat{\beta}_1 = -4.04\times 10^{-7} \hspace{15mm} t^* = 1.96 \hspace{15mm} SE_{\hat{\beta}_1} = 1.28\times 10^{-7}\]
\[ -4.04\times 10^{-7} \pm 1.96 \times 1.28\times 10^{-7} = (-6.55\times 10^{-7}, -1.53\times 10^{-7}) \]
95% CI for the slope: Computation
tidy(spotify_fit, conf.int = TRUE, conf.level = 0.95) |>
kable(digits = 10, format.args = list(scientifi = TRUE))|>
row_spec(2, background = "#D9E3E4")| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 | 7.268029e-01 | 8.350365e-01 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 | -6.557000e-07 | -1.520000e-07 |
We are 95% confident that, as the duration of a song increases by 1 millisecond, the danceability of that song will decrease by \(1.53\times 10^{-7}\) to \(6.56\times 10^{-7}\) units.
Complete Exercises 8-9.
Recap
Learned how to use mathematical models to
calculate confidence interval for the slope
conduct a hypothesis test for the slope