# load packages
library(tidyverse) # for data wrangling and visualization
library(broom) # for formatting model output
library(scales) # for pretty axis labels
library(knitr) # for pretty tables
library(kableExtra) # also for pretty tables
library(patchwork) # arrange plots
# Spotify Dataset
spotify <- read_csv("../data/spotify-popular.csv")
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 20))SLR: Mathematical models for inference
Mathematical representation, visualized
\[ Y|X \sim N(\beta_0 + \beta_1 X, \sigma_\epsilon^2) \]
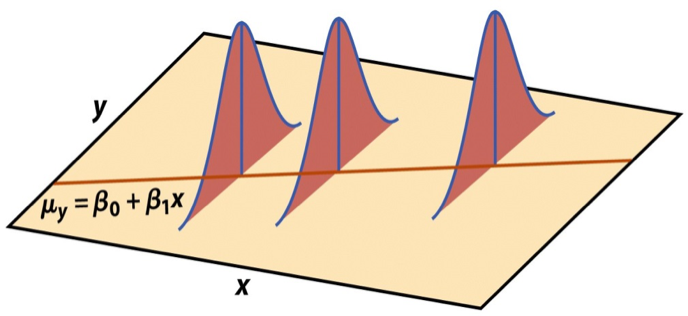
- Mean: \(\beta_0 + \beta_1 X\), the predicted value based on the regression model
- Variance: \(\sigma_\epsilon^2\), constant across the range of \(X\)
- How do we estimate \(\sigma_\epsilon^2\)?
Hypothesis test: p-value
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 7.809197e-01 | 2.754508e-02 | 2.835061e+01 | 0.000000e+00 |
| duration_ms | -4.039000e-07 | 1.282000e-07 | -3.150955e+00 | 1.723739e-03 |

Confidence interval: Critical value



Intervals for predictions
- Question: “What is the predicted danceability for a 3 minute (180,000 ms) song?”
- We said reporting a single estimate for the slope is not wise, and we should report a plausible range instead
- Similarly, reporting a single prediction for a new value is not wise, and we should report a plausible range instead

Comparing intervals

Complete Exercises 11 and 12.
Extrapolation
Using the model to predict for values outside the range of the original data is extrapolation.
Calculate the prediction interval for the danceability of a song which is 20 minutes (1.2 Million milliseconds) song.
No, thanks!

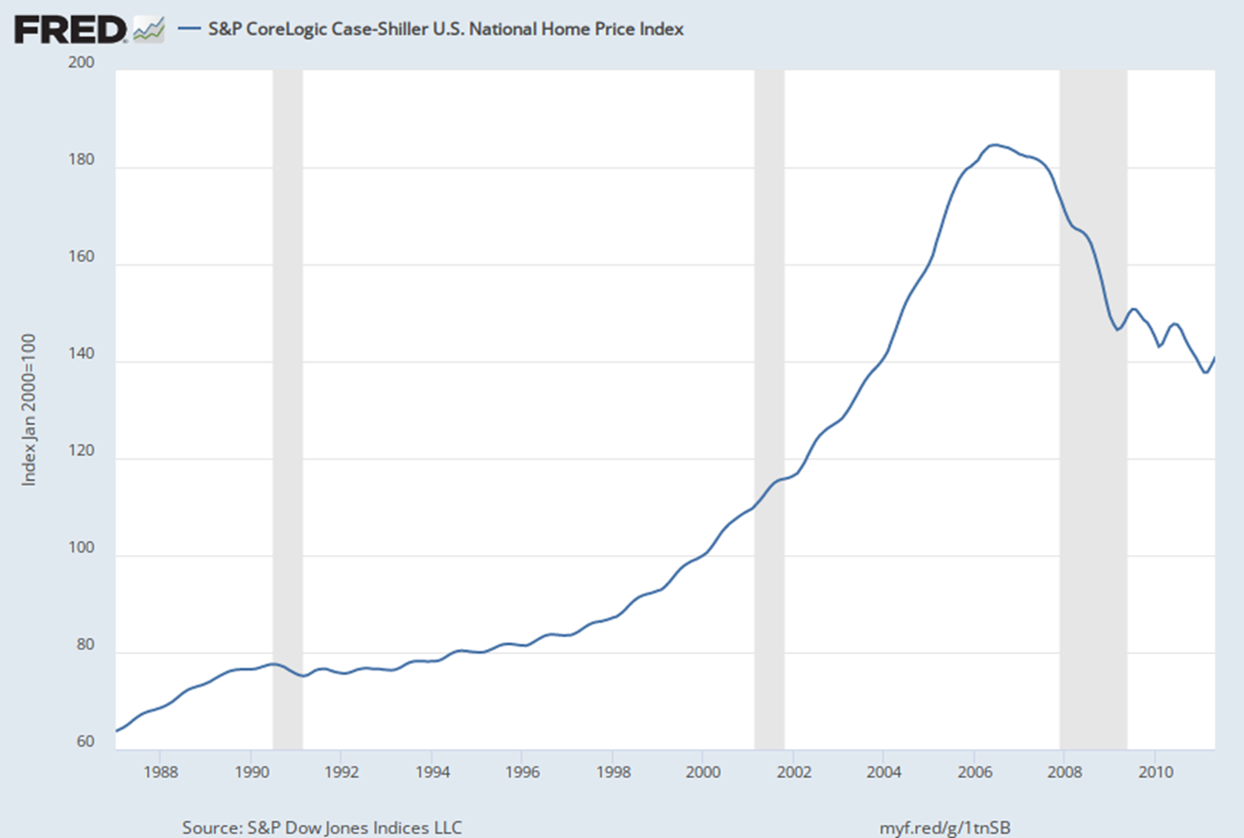
2005 be like: OMG HOUSING PRICES ARE GOING TO INCREASE FOREVER, YOUR CREDIT DOESN’T MATTER
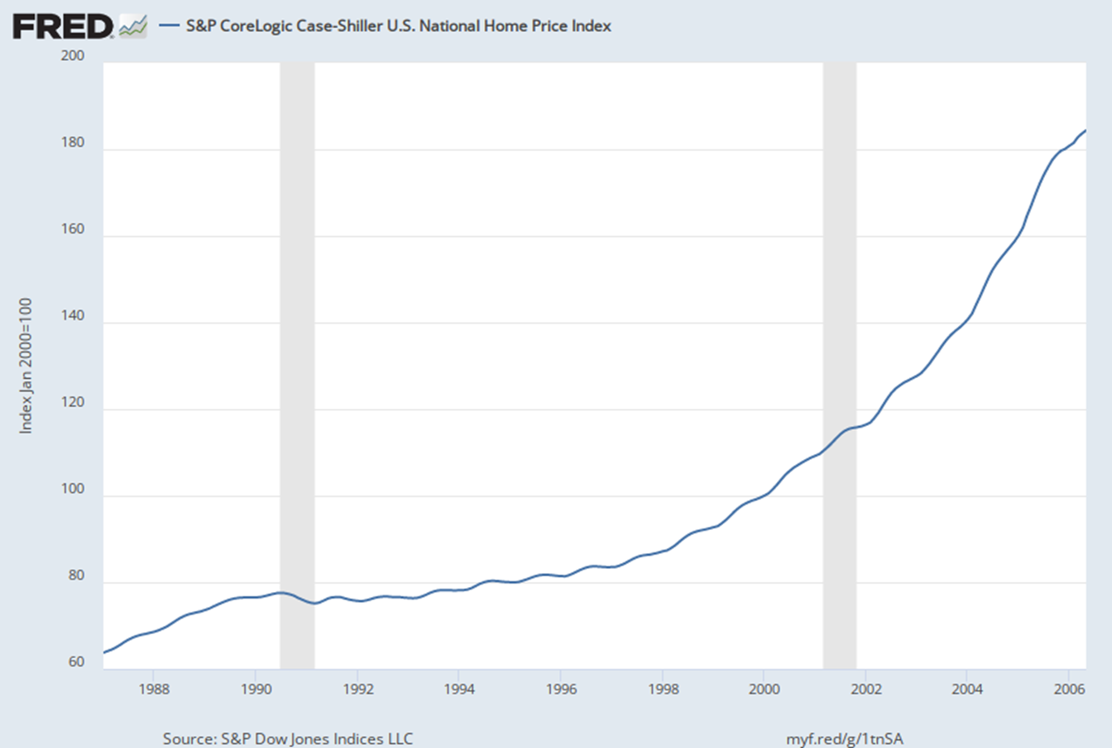
2007 be like: LOL NO